Title here
Summary here
12 avril 2023 par Martin Catty5 minutes
Avec plus de 100 sessions, le summit AWS offre l’opportunité à chacun de se créer son propre programme. Le nôtre était orienté autour de nos sujets de prédilections : les conteneurs, le stockage et l’orchestration.
Pas d’hésitation possible, vu la foule on était certain d’être au bon endroit. Côté organisation les équipes étaient bien calibrées pour gérer le flux de personnes venues assister aux conférences.

Même si les files étaient imposantes on a pu rentrer assez vite. Petite désillusion toutefois côté Grand Amphitéâtre qui faisait salle comble pour la keynote d’ouverture.

Heureusement nous avons pu nous rabattre dans une autre salle proposant une retranscription en live. Bien qu’amputés de la première partie de la conférence nous avons pu retrouver quelques un de nos clients prendre place tour à tour sur scène pour vanter les mérites du passage dans le Cloud chez AWS.

Pas de grande découverte pendant ces passages sur scène millimétrés : AWS offre une panoplie de services adaptés à tous les enjeux, qu’on soit primo entrant dans le cloud ou utilisateurs aguerris.
Pour les premiers c’était l’occasion de rappeler que la dynamique de migration dans le cloud est loin d’être un processus terminé. Pour nous qui y baignons depuis plusieurs années et pour qui cela semble acquis, la présentation d’Alix Boulnois, chief digital officer d’Accor, nous offre une vision tout autre avec un taux de pénétration du cloud dans les sociétés d’hôtellerie qui avoisine les 27% seulement.

Première session technique avec la présentation des différentes options qui s’offre à nous lorsqu’on a besoin de stocker des données avec AWS (hint: elles sont nombreuses).
On a donc parlé d’EBS et de ses différentes options possibles (gp2, gp3…).

Mais également de EFS (service de NFS aux performances et dimensionnement élastique).
Enfin nous avons eu droit à un projet mettant en scène de la recopie de données sur site vers AWS via FTP, traitement des données, création de requêtes sur mesure sur ces données et affichage de tableaux de bord.
Le tout aura mobilisé pas moins de 4 services, avec une intégration assez simple : Datasync, Glue, Athena, Insights.
Nous avons aussi eu droit à une présentation des coulisses d’un court métrage créé par AWS, Picchu.

Il s’agissait de mettre en avant le fait que les studios n’ont plus besoin de maintenir des infrastructures internes lourdes et couteuses pour traiter les fichiers RAW en présentant notamment les services de liens de transfert spécifiques et file cache.
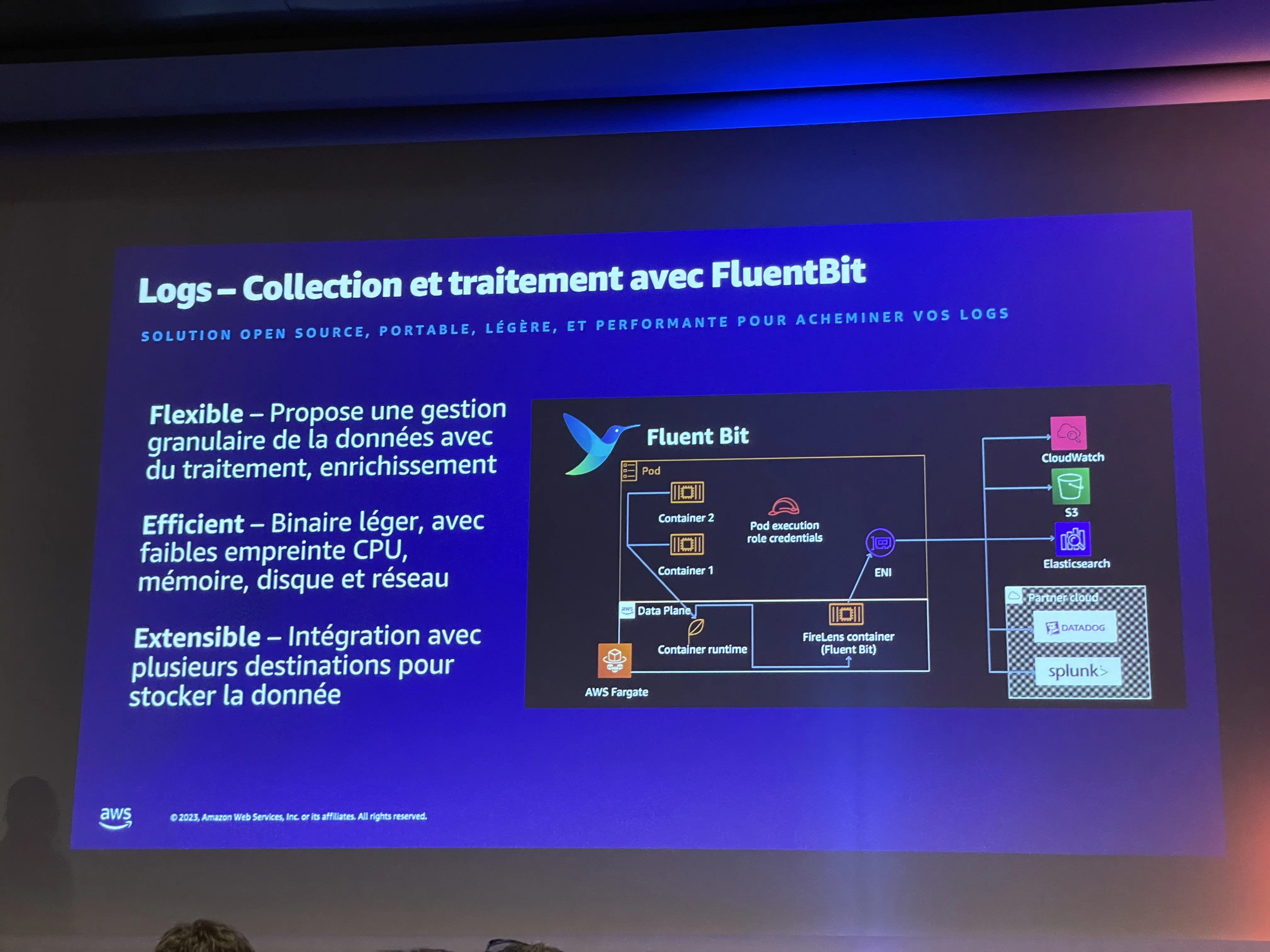
Dans cette première session autour de Kubernetes nous avons eu droit à une présentation orientée observabilité.

L’occasion de nous rappeler la présence de tout un tas de module «blueprint» disponible pour EKS. Les blueprint représentent des intégrations tierces disponibles sur étagère, pour EKS mais pas que.
On peut de fait les activer très simplement au sein de modules Terraform.


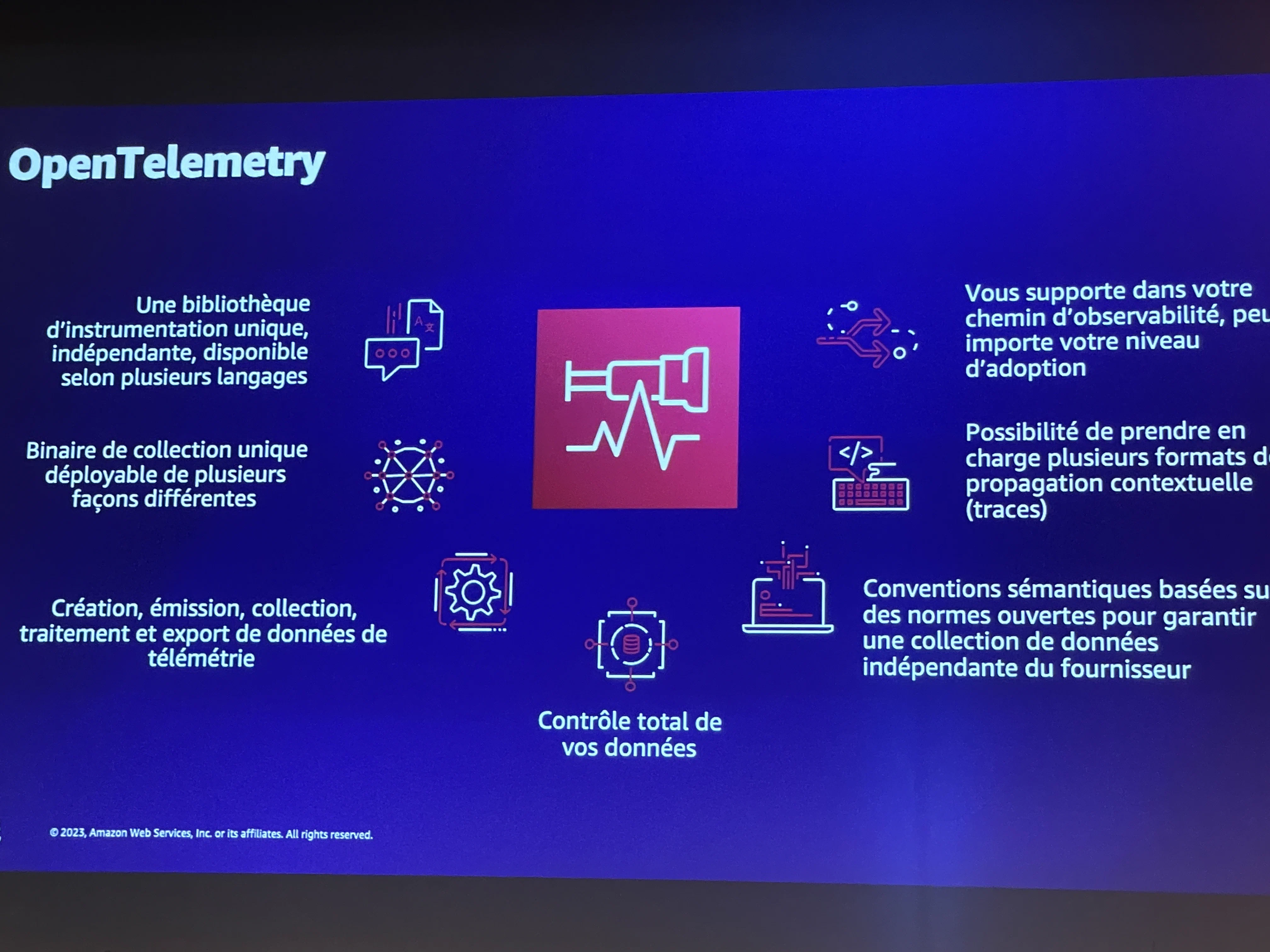
La session a fait un focus important sur OpenTelemetry qui devient le standard de facto pour tout ce qui a trait à l’observabilité autour des 3 piliers suivants : logs, traces et métriques.
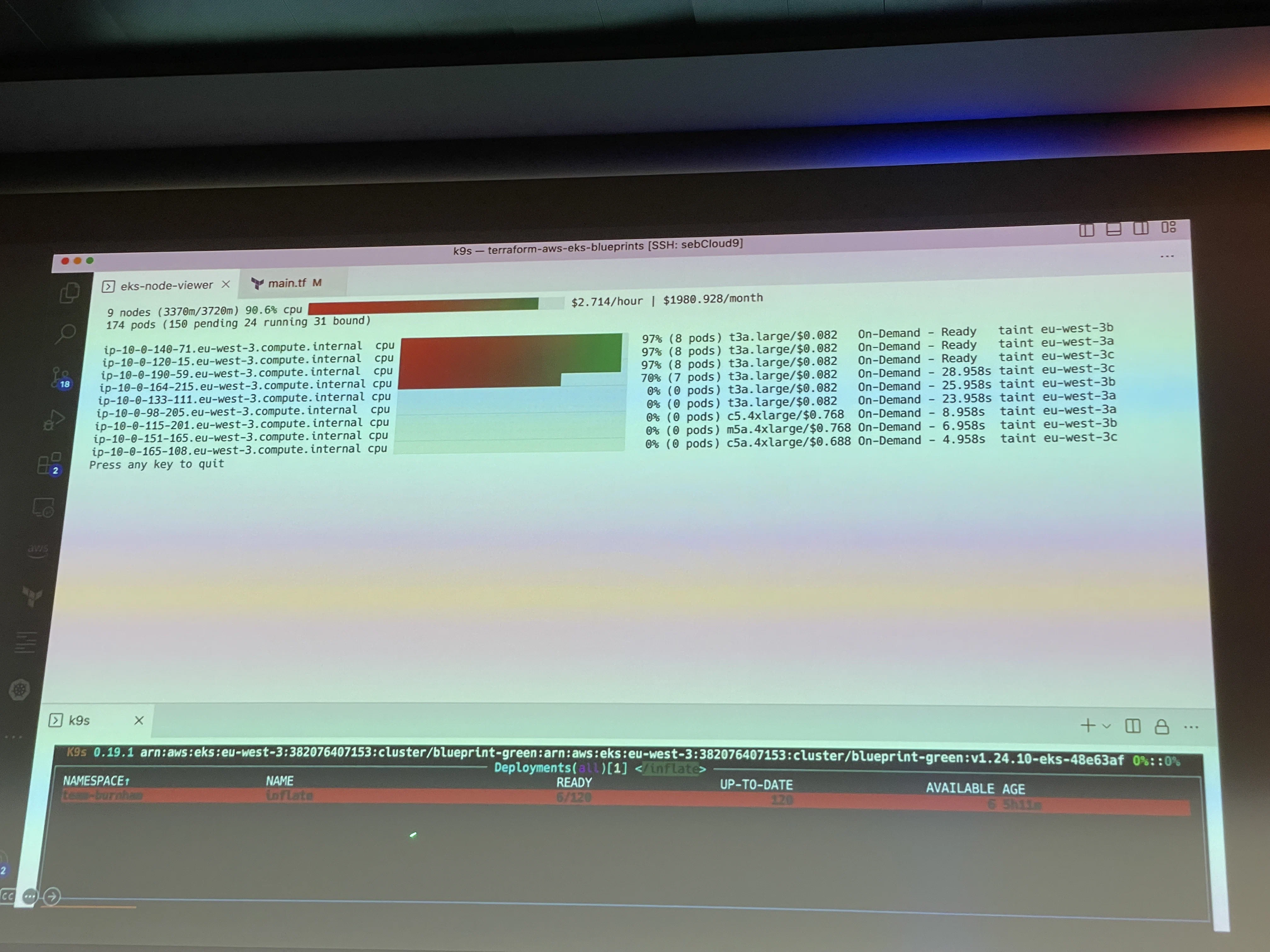
Sans doute la conférence la plus intéressante à laquelle on ait assisté. Il s’agissait de montrer comment dimensionner et optimiser un cluster EKS avec l’outil Karpenter.
L’outil dans un premier temps développé de façon autonome va bientôt devenir partie prenante de l’offre Kubernetes managé d’AWS, EKS.
Cette solution offre des possibilité de dimensionnement dynamique du cluster selon la charge. Vous vous demandez sans doute en quoi ce service est différent de l’autoscaling ?
Il s’git ici d’offrir le meilleur ratio performance / coût. Concrètement le service permet d’utiliser plusieurs types d’instance et de rationaliser la charge.
Si mon service tourne actuellement sur 2 instances Mx alors qu’il pourrait tourner sur une seule instance Tx moins chère le service ajustera automatiquement les noeuds de mon cluster.

La démo était particulièrement intéressante en montrant des montées en charge de quelques pods à plus de 6 000. L’outil offre également un instantané du coût mensuel.
Plutôt que de garder quelques noeuds avec moins de 50% de charge utile, le système reschedule les pods sur 1 seul noeud pour maximiser l’efficacité. Il permet également, via configuration, l’utilisation de noeud spot permettant de faire dimuner la note.
Au final l’instantané de facturation passait de +6000$ à moins de 2000. Définitivement un outil sur lequel on va se pencher sérieusement.

La recherche classique par token est basée sur l’utilisation de mots-clés pour trouver des informations pertinentes. C’est le comportement par défaut d’un moteur de recherche, cependant elle ne prend pas en compte la signification ou le contexte des mots, ce qui peut entraîner des résultats de recherche imprécis ou incomplets.
En revanche, la recherche sémantique avec Elasticsearch utilise des algorithmes avancés pour comprendre la signification des mots et leur contexte. Elle permet ainsi de fournir des résultats de recherche plus précis et pertinents, en prenant en compte la sémantique, les synonymes, les homonymes et les relations entre les mots.
Cela a bien été illustré en prenant en exemple le cas de recherche dans un contexte e-commerce. Même si cela est acquis pour toute personne mettant en place un moteur de recherche, cette piqûre de rappel était nécessaire.
Mais aussi l’occasion d’échanger avec les uns et les autres (on y a retroué Suse, Gitlab…) et de faire d’étonnantes découvertes au gré de nos pérégrinations comme le robot spot de Boston Dynamics en balade dans les allées.

Mais également un compteur de cafés serverless.
Ou encore un concours de tir au but avec un terrain bardé de capteurs.
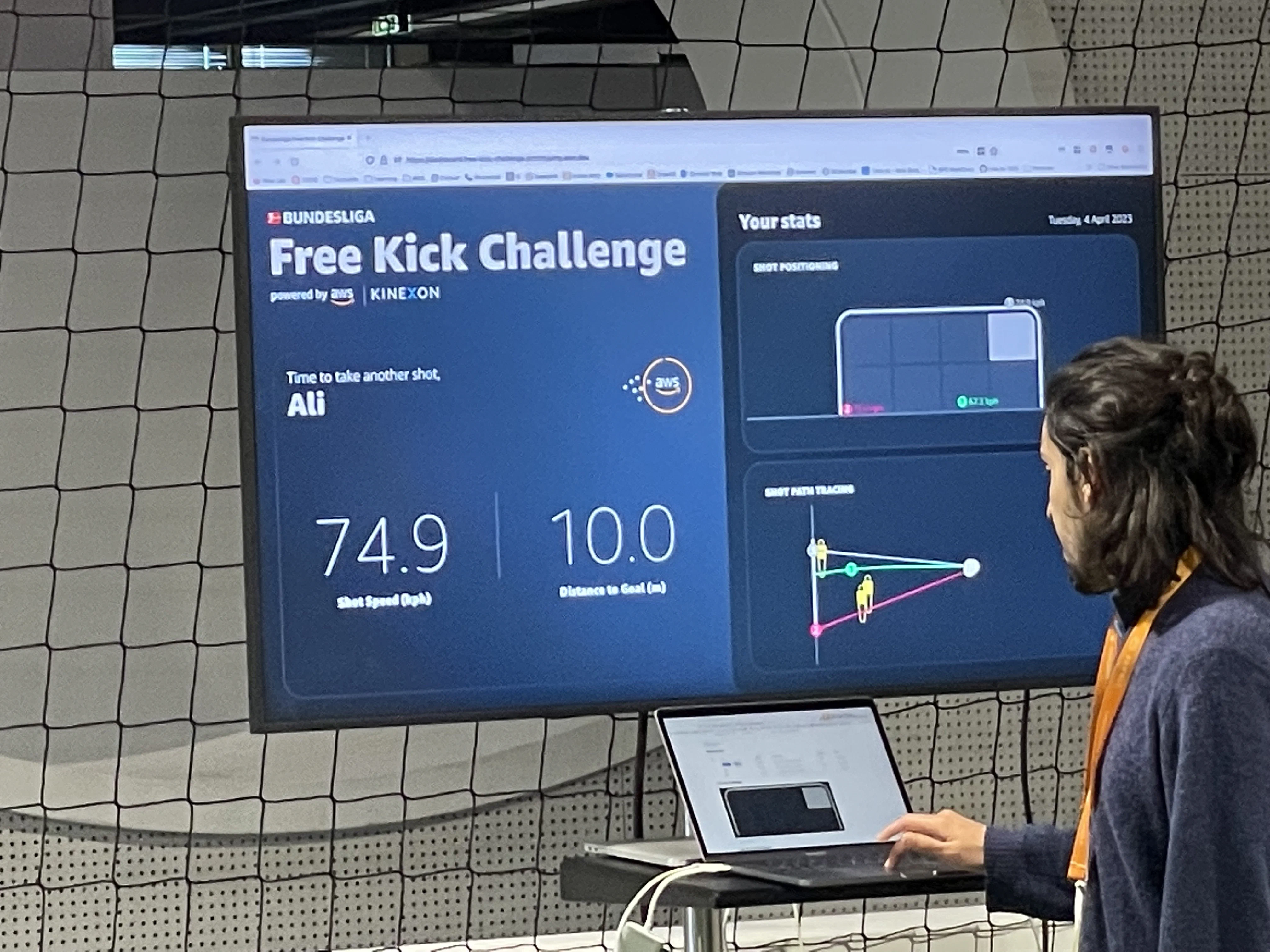
Encore une belle édition pour ce summit AWS. On en repart rechargés à bloc mais également un peu frustrés de ne pas avoir pu en voir plus. On aurait notamment aimé savoir ce qui se trame côté AI mais pour cela on attendra la publication des conférences en ligne.